上一篇的核心發現是:AI 改變的不是打字速度,而是工作流瓶頸的位置——從「寫 code」轉移到「review」。Reviewer 的認知頻寬沒因為 AI 變大,但你的產出多了好幾倍。Codex 團隊把 PR 拆得小(中位數 5 檔/118 行)、合得勤(一天 19 個),就是為了不讓這個新瓶頸塞住。
但這個答案會立刻引出下一個問題:
OK,小修改可以拆得這麼小。但如果是跨模組的大型重構呢?把一個型別推廣到整個 codebase、把一個模組搬到另一個 crate、refactor 一整套架構——這些事情自然就跨幾百個檔案。它們怎麼可能塞進 5 個檔案?
這個問題其實就是上一篇 thesis 的極端形式:如果 review 是新瓶頸,那一個 200 檔案的重構 PR 會發生什麼事?答案很明顯——一次把整個 review 預算用光,瓶頸瞬間爆炸。Reviewer 沒辦法真的理解這 200 個檔案在改什麼,只能蓋章放行。原本想做「有效建設」,結果變成在 main 上埋 200 個檔案的不確定性。
所以我去翻了 git log,看 Codex 怎麼處理這個極端場景。
結論是:這些「大型重構」在 Codex 的 main branch 上,根本不以「一個大 PR」的形式存在。它們被拆成一系列獨立的小 PR,每個都不超過 5-20 個檔案的「review 預算」,而且每個合進去之後 main 都是完整可用的。

讓我用三個真實案例帶你看這個拆分過程。
案例一:AbsolutePathBuf 的 4 個月滲透
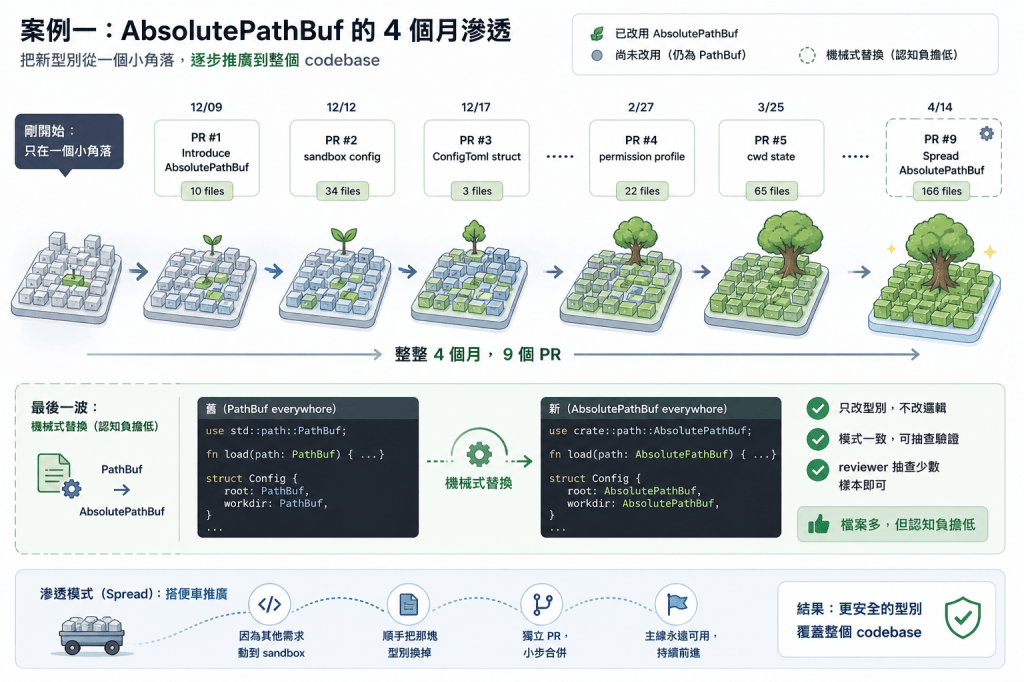
Codex 在 2025 年 12 月引入了一個新型別 AbsolutePathBuf,用來取代原本到處用的 PathBuf。目標是 codebase 裡所有「絕對路徑」的場景都改用這個更安全的新型別。
聽起來簡單,但實際影響數百個地方。如果一次推,會是一個 200+ 檔案的 PR。
他們的做法:
| 日期 | PR | 檔案數 | 做什麼 |
|---|---|---|---|
| 12/09 | Introduce AbsolutePathBuf | 10 | 定義新型別,在 config 解析中首次使用 |
| 12/12 | sandbox config | 34 | 推廣到 sandbox 模組 |
| 12/17 | ConfigToml struct | 3 | 推廣到 config struct |
| 2/27 | permission profile | 22 | 推廣到權限模組 |
| 3/25 | cwd state | 65 | 推廣到 cwd 處理 |
| 4/07 | joins infallible | 40 | 讓 join 操作不 panic |
| 4/08 | exec cwd plumbing | 31 | 推廣到 exec 模組 |
| 4/13 | skill loading | 86 | 推廣到 skill 載入 |
| 4/14 | Spread AbsolutePathBuf | 166 | 最後一波掃尾 |
整整 4 個月、9 個 PR,才把這個型別「滲透」完。
幾個關鍵觀察:
第一個 PR 只改 10 個檔案——定義型別 + 在一個小範圍首次使用,證明可行性。沒有試圖一次解決所有問題。
中間幾個 PR 是「順便推廣」——這個叫 spread 模式。當開發者因為其他原因要動 sandbox 模組時,順手把那塊也用 AbsolutePathBuf 替換掉。沒有專門排時間做這件事,搭便車而已。
最後一個 PR 改了 166 個檔案——但那是純機械式替換。Commit message 直接寫:「Mechanical change to promote absolute paths through code.」這種 PR 雖然檔案多,但 reviewer 的認知負擔很低——只要抽查幾處確認模式一致就好。
這帶出第一個重要原則——PR 的「大小」要看認知負擔,不是檔案數。
案例二:MCP Apps 的多 Part 系列
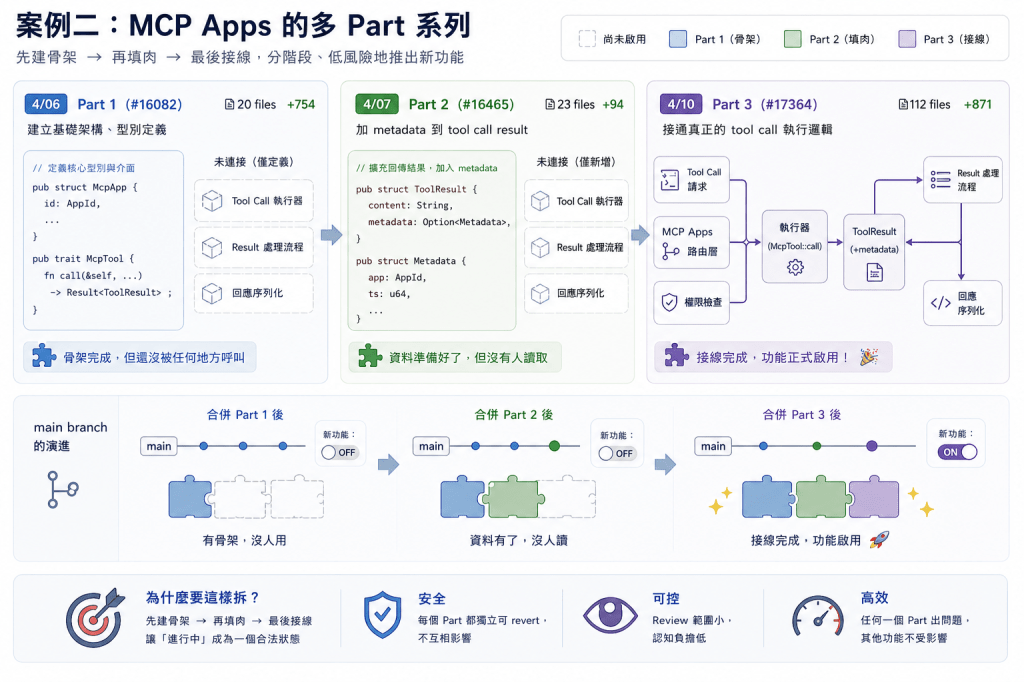
不是所有重構都能搭便車。有些重構是「先有骨架才能填肉」,需要明確的順序。
Codex 在實作 MCP Apps 支援的時候用了這種模式:
| 日期 | PR | 檔案 | 行數 | 做什麼 |
|---|---|---|---|---|
| 4/06 | Part 1 (#16082) | 20 | +754 | 建立基礎架構、型別定義 |
| 4/07 | Part 2 (#16465) | 23 | +94 | 加 metadata 到 tool call result |
| 4/10 | Part 3 (#17364) | 112 | +871 | 接通真正的 tool call 執行邏輯 |
策略是:先建骨架(Part 1 放型別和介面),再填肉(Part 2 補 metadata),最後接線(Part 3 接通執行路徑)。
這個拆法有個微妙的地方——Part 1 和 Part 2 合進 main 後,新功能還不會啟用。型別定義出來了但沒有呼叫者;metadata 加上了但沒有人讀取。要等 Part 3 才整體啟用。
這聽起來怪怪的——為什麼不一起推?因為這樣做有一個關鍵好處:任何一個 Part 出問題,其他 Part 都不受影響。Part 1 如果有 bug,可以單獨 revert,Part 2 不會壞。Review 也比較輕鬆——三個小 PR 各自審 100 行邏輯,比一次審 1000 行容易得多。
案例三:用「絞殺者模式」抽出獨立 crate
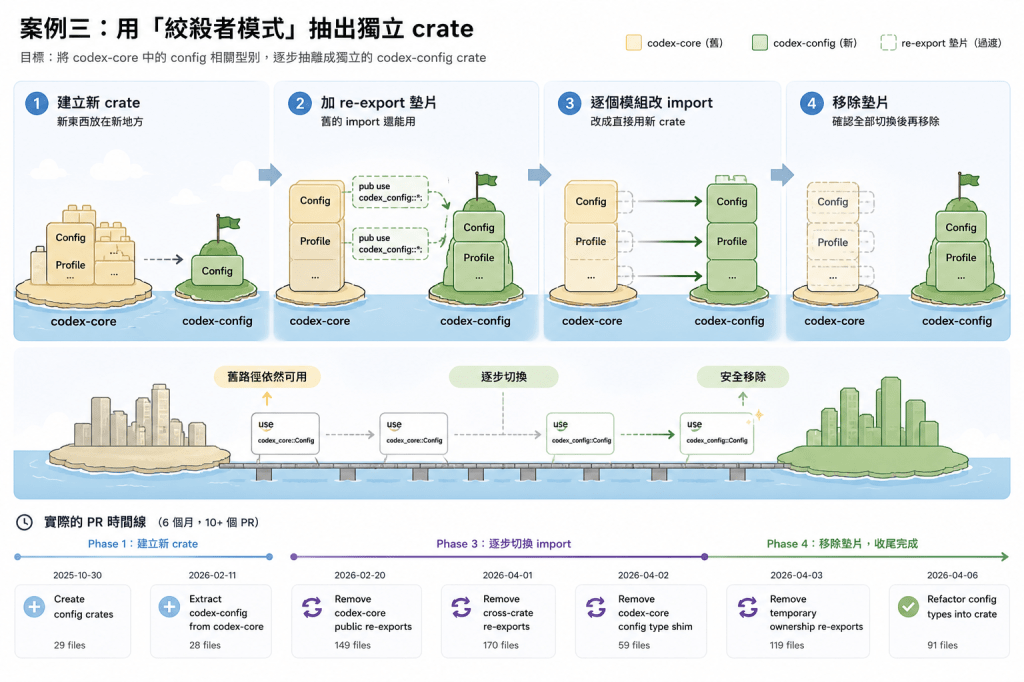
最複雜的一種大重構是模組拆分——把一個 crate 裡的東西抽出來變成獨立 crate。
Codex 在 6 個月內把 config 相關的型別從 codex-core 抽成獨立的 codex-config crate。這個過程涉及 10+ 個 PR、數百個 import 路徑變更。
他們用的是 Strangler Fig Pattern(絞殺者模式),分四個階段:
Phase 1: 建立新 crate(新東西放在新地方) ↓Phase 2: 在舊 crate 加 re-export 墊片(舊的 import 還能用) ↓Phase 3: 逐個模組改成直接 import 新 crate ↓Phase 4: 確認所有 import 都切換完,刪除墊片
實際的時間線:
2025-10-30 Create config crates 29 files, Phase 12026-02-11 Extract codex-config from codex-core 28 files, Phase 12026-02-20 Remove codex-core public re-exports 149 files, Phase 32026-04-01 Remove cross-crate re-exports 170 files, Phase 42026-04-02 Remove codex-core config type shim 59 files, Phase 42026-04-03 Remove temporary ownership re-exports 119 files, Phase 42026-04-06 Refactor config types into crate 91 files, 結構確立
這個策略的關鍵在 Phase 2 的 re-export 墊片。它讓舊的 use codex_core::Foo 在過渡期間仍然能編譯。所以當 Phase 3 在逐個改 import 路徑時,沒改到的地方靠墊片繼續運作,main 從頭到尾保持綠燈。
只有在 Phase 3 確認所有 import 都已切換後,Phase 4 才安全地移除墊片。
這就是「絞殺者模式」的核心精神——新的東西像藤蔓一樣慢慢爬滿舊的結構,等它完全長好了,舊的才被完全取代。
三個案例背後的共同原則
把這三個案例放在一起看,會發現一個共同模式:
大型重構不是「一次做完」的事,是「一系列原子操作」的累積。
每個 PR 都是一個原子操作:
- 獨立可 merge——不依賴其他未完成的 PR
- 合進 main 後系統依然完整可用——沒有「half-done」的中間狀態
- 可以獨立被 revert——不會牽連其他 PR
要做到這三點,他們用了三種「過渡機制」:
| 過渡機制 | 作用 | 案例 |
|---|---|---|
| 新增不修改 | 新型別/介面先建立,舊的不動。等接線時再啟用 | MCP Apps Part 1、Part 2 |
| Re-export 墊片 | 舊的 import 路徑仍然有效,等所有人改完再刪 | Config crate 抽離 |
| Feature flag | 新功能藏在 flag 後面,不影響預設行為 | 各種半成品功能 |
這些過渡機制的本質都一樣:讓「進行中」變成一個合法狀態。傳統做法是「要嘛舊的、要嘛新的」,重構期間沒有合法的「過渡狀態」,所以必須一次推完。Codex 的做法是設計一個「新舊並存」的中介狀態,重構就可以在這個狀態下慢慢進行,不需要一次完成。
從上一篇的瓶頸視角看,這三種機制其實在做同一件事——把一次性會壓垮 review 的大改動,分散到多個 review 預算內可消化的小改動裡。每個 PR 都還在 reviewer 的認知頻寬之內,整體加起來才完成大重構。Reviewer 從來不需要「一次理解 200 個檔案」,只需要連續理解 10 次「20 個檔案」。
再強調一次:PR 大小看認知負擔,不是檔案數
回到開頭的問題——為什麼 Codex 的 PR 中位數可以是 5 個檔案?
答案不是「他們不做大重構」,而是:
他們的「大」用的是另一種衡量——認知負擔。
| 改動性質 | PR 可以多大? |
|---|---|
| 有邏輯變更(新功能、改行為) | 必須小,目標 ≤ 5 個檔案 |
| 純機械式替換(rename、type swap) | 可以大,100+ 檔案都行 |
| 搬移檔案 / 改 import 路徑 | 可以大,前提是有墊片保持舊路徑可用 |
那個 166 檔案的 AbsolutePathBuf spread PR、那個 170 檔案的 re-export 移除 PR——它們的「邏輯變更」其實是零。Reviewer 看 5 個典型 case 就能確認模式正確,不需要逐個檔案 review。
這跟「PR 不能超過 200 行」這種絕對規則不一樣。它是更精緻的判斷:reviewer 真的需要動腦的部分有多少?
為什麼這對 AI 時代特別重要
回到上一篇的 thesis:當 AI 加速產出,瓶頸從寫 code 轉移到 review。大型重構在這個轉移裡是最危險的場景——因為 AI 特別擅長「生成大量改動」。
你叫 AI 把整個 codebase 的 PathBuf 換成 AbsolutePathBuf?它一個下午就生出 200 個檔案的 diff 給你。問題是:這 200 個檔案誰來 review?
沒有絞殺式更新的紀律,AI 加速產出的後果是這樣的:
- AI 一次生成大型 PR → reviewer 看不過來 → 蓋章放行
- main 上累積一堆「我也不知道為什麼這樣寫」的程式碼
- 三個月後出 bug,
git blame指向那個 200 檔案的 PR——但沒人記得當時為什麼這樣改
這就是「寫得快但沒有轉化成有效建設」的標準失敗模式。AI 把產出量放大了,但 review 預算沒變,差距全部變成技術債。
Codex 的做法是把大重構分解成一系列小 PR 的紀律——這個紀律在前 AI 時代就重要,在 AI 時代是生存必需。它把 200 檔案的重構切成 10 個 20 檔案的 PR,每個都還在 reviewer 認知頻寬之內,total throughput 反而更高。
更深一層:AI 工具特別擅長執行「機械式替換」這種 PR——你給它一個明確的 pattern,它可以把整個 codebase 都按照那個 pattern 改一遍。但這要求人類先把「pattern」設計好、把「過渡機制」(墊片、feature flag)建立好。
人類設計重構的策略,AI 執行其中的機械步驟——這是 OpenAI 那篇 harness 文章描述的「Humans steer, agents execute」在大型重構場景下的具體形態。型別推廣那 166 檔案的 spread PR,幾乎可以完全交給 AI 執行;但「先建立 AbsolutePathBuf 型別、再規劃滲透順序」這個策略性決定還是人做的。
下一篇
到這裡為止,前兩篇都假設了一件事:「PR 過 review 之後 merge 進去的版本」就是「reviewer 看到的版本」。但對一個一天合 19 個 PR 的團隊來說,這個假設並不天然成立——你的 PR 在 review 期間,main 已經被別人 merge 過好幾次了。Reviewer 看的是舊 snapshot,merge 進去的是疊加了新東西的合成體。這個現象叫 review drift。
下一篇要講 Codex 怎麼用兩個強制規則(squash merge + rebase before merge)把 drift 鎖住,讓 review 的承諾可以兌現——也讓絞殺式更新的「中介狀態」真正可推理。線性歷史不是為了好看,是讓前兩篇的紀律有地基可站。

發表留言